一、设计说明
设计这个自动化的目的是想要交替、重复地使用固定的几个分区(分区编号01~05)来保存数据,当最后一个分区就是快满的时候,我们会把最旧数据的分区的数据清空出分区,新数据就可以使用老分区空间了。
应用这个自动化管理分区的环境是有些限制的,其一:分区的数据是呈现递增的,比如分区字段是自增Id值,或者是以日期作为分区;其二:可以接受历史数据被移除分区表带来的问题。其三:一天进库的数量不应大于分区管理表PartitionManage中Part_Value与Change_Value的差,因为我们作业执行的频率是1天,不过你可以调整Change_Value或者作业的执行频率;
具体脚本可以参考:SQL Server 2005 自动化删除表分区设计方案
二、看图说话
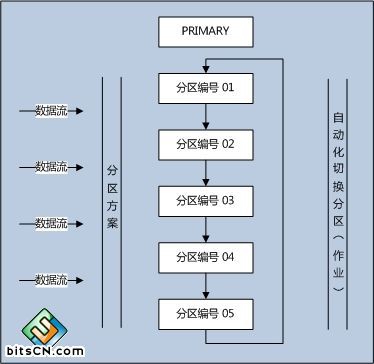
(图1:整体概念图)
数据流经过分区方案,被分配到不同的分区中,从图中可以看出,分区是可以重复利用的,后台有一个所谓的自动化切换分区的作业在跑,目的就是如果重复利用这些分区。这里的PRIMARY目的就是说明它与其它文件组的一个平级关系,而且我们在做交换分区时候也会用到PRIMARY,需要事先分配足够的空间。
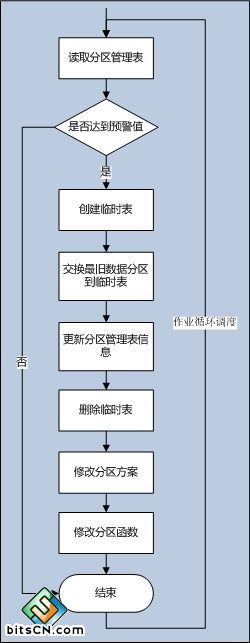
(图2:自动化设计图)
这是自动化切换分区作业的逻辑处理,其中分区管理表的设计是比较重要的,它的灵活度关系到整个自动化的效果; 这个逻辑有以下几个特点:
1. 分区的索引进行存储位置对齐;其它索引在创建时就使用了分区方案,索引数据跟随分区数据一起存储在分区中;
2. 分区管理表,包含了分区记录数预警设计,在Id达到这个值后就会进行交换分区;
3. 分区管理表,FileGroup_String字段的数据可以通过SQL脚本自动化生成,条件就是分区文件组名称需要有规律;
4. 临时表是创建在PRIMARY主分区上,跟原表使用相同的分区方案;需要事先给PRIMARY分配大于或者等于一个分区文件大小的空间,这样在交换分区的时候就不用增量为主分区分配数据空间;
5. 交换旧数据到临时表,使用下面的语句可以把数据交换到相同的分区中编号,这样可以应对临时表就是一个历史表,而好处就是历史表也同样使用了分区。
ALTER TABLE [tb] SWITCH PARTITION @PARTITION_num TO [Temp_tb] PARTITION@PARTITION_num
6. 这里需要先修改分区方案,才能修改分区函数,这个跟创建分区函数与分区方案的顺序是刚好相反的。
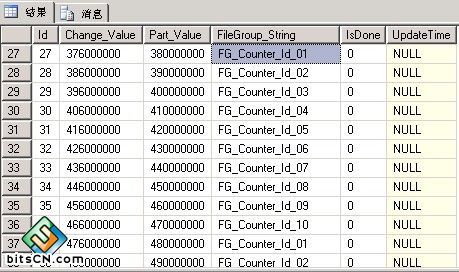
(图3:分区管理表PartitionManage)
字段说明:Change_Value(预警Id值)Part_Value(分区函数值)FileGroup_String(分区文件组名称)IsDone(状态)UpdateTime(更新时间);
这就是那个分区管理表(PartitionManage),它是经过了几个版本后才把字段确定下来的,现在它已经比较完善了,能应对比较多的情况:
1. 比如我们可以修改预警值(Change_Value),让数据提早进入交换分区;
2. 比如我们可以修改分区值(Part_Value),达到调整分区间隔的目的;
3. 比如我们可以修改分区文件组名称(FileGroup_String),达到跳级文件组的目的;通过修改分区管理表来设置分区值与分区文件组的对应关系;
4. 再比如,我们一次性修改了分区方案和分区函数,已经去到很后面的分区值了,那么我们只要设置这些分区值的状态(IsDone)为1(True)就可以解决了。
5. 记录了进行交换分区的时间(UpdateTime),方便查询;
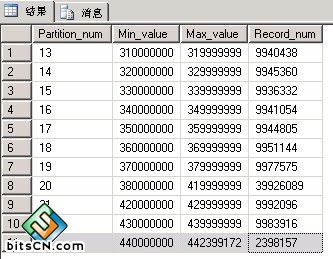
(图4:分区为Id字段的记录分布图)
这是一个实战中的分区情况,这样的分区特点就是分区里面的记录数基本上是持平的,在Partition_num=20的记录中明显多了很多记录,这就是因为我们没有及时进行交换分区造成的。
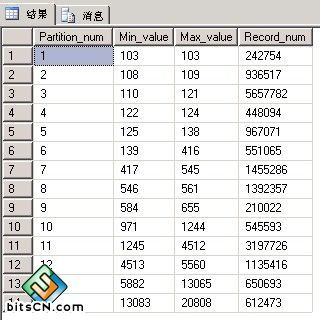
(图5:分区为ClassId(分类)字段的记录分布图)
这同样是另外一个生产环境中的真实数据,这个分区方式的特点就是分区的记录数不太均等,而我们前期需要做的就是通过划分每个分区中ClassId的值来尽量均衡分区中的记录数,所以可以看到最小与最大值跨度区别是比较大。