因为现在很多人在做自己的论坛,为了对他们有些帮助,我打算把我优化论坛的步骤写下来。 文章会分为好几篇来写,由于涉及的细节很多,我自己也是在边写帖子边给论坛做SEO优化,所以我也不知道会写到什么时候结束。
1,选择论坛程序和版本。
我选择的论坛程序是Discuz! x1.5,语言版本是 gbk 版。为什么选这个版本呢?
首先Discuz!x1.5的用户体验要比Discuz!7.2好很多,大家慢慢用这个论坛就会发现这一点。然后Discuz!x1.5的SEO基础也要比Discuz!7.2好。其实Discuz!7.2是有很多SEO上面的缺陷的,以前那个老论坛我想做一下SEO优化,但是发现要改的还真不少。但是Discuz!x1.5注意到了很多对SEO不友好的地方,如很多容易产生重复的链接就用JS调用等等。
显然 Discuz! x1.5 的开发团队做事非常用心,让我也对改这个论坛程序有信心很多。
那为什么要选GBK版本而不选UTF8版本呢? 这是为了让中文搜索引擎第一时间知道我网站上的内容是中文版本。
爬虫在GBK编码的网页,看到的是:
| <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="Content-Type" content="text/html; charset=gbk" /> |
而在utf-8编码的网页看到的是:
|
<html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> |
Utf-8编码的网页,一时半会还真不知道这个网站里的内容是什么语言的,而且如果一个网页中有中文和有英文的时候,搜索引擎还要根据其他一些条件来判断网站的语言版本。而GBK版本一看就知道是中文的了。
大家如果去查看一下的话,Discuz官方论坛用的就是GBK版本。
那已经在用utf-8的中文discuz论坛怎么办呢? 其实还是有方法解决的,可以定义一下xmlns 属性,把 lang="zh-CN" 加在里面就可以了。 所以utf-8版本的代码变为:
| <html xmlns="http://www.w3.org/1999/xhtml" lang="zh-CN"> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> |
Discuz论坛很多文件都需要这么改,可以用Dreamweaver整站查找一下。很多其他网站也一样。这样改好后,搜索引擎能识别这个网页为简体中文版。
2,选择服务器系统
我是很早就不想用windows做服务器操作系统了,只要体会过linux系统好处的人恐怕都是如此。其实,选择什么样的服务器系统也能影响SEO效果的。我最近给很多大中型网站做SEO顾问的时候据发现一个很有趣的规律: 凡是用windows类系统搭建的网站,SEO方面的表现都是不太理想的,而且要优化起来难度也是大一些的。
原因是很多方面的,因为windows类主机不是很稳定,只要程序员不那么熟悉整个网站,要么被动的频繁当机、要么需要主动停机维护、要么数据库压力大以及运行的代码先天不足导致服务器速度非常慢。 我观察过很多网站的爬虫访问情况,在同等条件下,windows类主机的抓取量都是差一些的。
当然,这个问题在一个资深的技术人员手里都不是问题,但就是优秀的技术人员实在太难找到了。
3、优化网站的访问速度
网页的加载速度对SEO影响比较大。优化网站的加载速度,可以从以下几个方面来优化。
1)DNS
2)服务器网络环境
3)服务器硬件和系统
4)网站程序或CMS
5)前端代码
这些因素不用去记的,基本上就是看爬虫从发起一个请求到返回数据,中间需要经过哪些途径,然后优化这些相关因素即可。
现在这个论坛只优化了2个地方,就是是DNS优化和网页打开GZIP压缩。因为用的是现成的程序,其他地方都不太差,暂时先解决一些基本的问题。
DNS上的优化,就是启用了双线主机以及智能DNS。 为什么我要先做这个呢? 因为我想优化百度爬虫访问我网站的速度。
因为这是中文论坛,做SEO优化肯定要以百度优先。
因为很多人还是没有养成先看数据再来做SEO的意识,所以在优化速度的过程,有个问题没注意到的。这就是没有看看爬虫到底是从什么地方来访问的。 对于大部分中文网站来说,爬虫可能90%以上都是从北京联通(网通)访问过来的。这个时候就要特别优化北京联通(网通)的访问速度。
所以我用的双线机房有2个IP,一个电信的IP和一个联通(网通)的IP。有了个2个IP,还要做智能DNS,这样当电信的用户访问论坛的时候,就解析到电信的IP上,联通的用户访问论坛的时候就解析到联通(网通)IP上。 这样,百度爬虫从北京联通访问我论坛的时候,速度就快很多了。 我用的智能DNS服务是DNSPod(http://www.dnspod.com/)提供的,设置的界面如下:
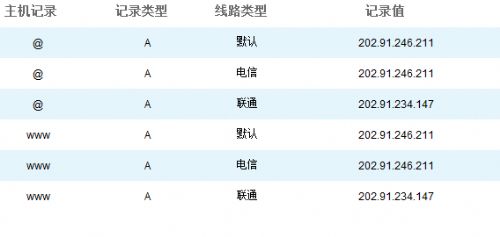
我在DNSPod里面的账户是免费账户,收费账户应该速度更好一点,但是DNSPod对于收费账户还要审核,我就一直没升级了。
设置好了以后,还要检查一下到底优化的效果如何。 可以用监控宝(http://www.jiankongbao.com/)的工具检测一下。以前北京联通的响应速度是 1831 ms。经过优化,速度确实会提高很多,如:
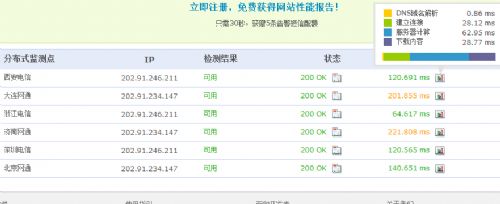
这里还列出了是哪方面影响速度的因素大。最好是长期监测这个响应速度,因为这个因素的变化能比较大的影响到SEO效果。可以注册成为这个网站的付费用户,就可以每隔几分钟去检测一下网页的响应时间等等。
为了加快前端的速度,我启用了论坛自带的gzip压缩。Discuz!x1.5后台现在还没有启用gzip压缩功能的地方,需要手动设置:
打开 /config/config_global.php 文件,把
| $_config['output']['gzip'] = '0'; |
改为
| $_config['output']['gzip'] = '1'; |
即可启用gzip压缩。
Discuz! x1.5后台还可以做一些速度上的优化如启用memcache等等,但是这个相对麻烦点,留着下次来做。
4,静态化URL
Discuz! x1.5后台自带了一个静态化URL的功能,而且默认也写好了静态化的规则。但是这里有一个问题,就是帖子页面的静态化规则没有写好。
如默认的帖子页面规则是:
| thread-{tid}-{page}-{prevpage}.html |
即规则为:
| thread-{帖子ID}-{帖子翻页ID}-{当前帖子所在的列表页ID}.html |
问题就出在“当前帖子所在的列表页ID”这里,因为在论坛板块中,当一个帖子是最新发表或最新回复的时候,“当前帖子所在的列表页”是第一页,url中的数字是 “1”。当这个帖子很久没人回复沉下去的时候,“当前帖子所在的列表页”就不知道是几了,可能出现在第二页,也可能在第十页。这样,每个帖子的url经常在变化。会产生很多的重复页面,而且url经常变化,当前帖子积累的权重会丢失。
为了解决这个问题,可以重写url静态化规则。当然修改页面代码也能解决这个问题,但是不方便维护,因为修改后的文件以后可能会被升级文件覆盖,而且会丢失部分功能。
论坛用的是linux+apache,而且论坛是作为一个虚拟主机放在服务器上。 Url静态化的过程就这么操作:
新建一个文本文件,文件名为“.htaccess”,然后用UltraEdit编辑这个文件,写入的规则为:
|
# 将 RewriteEngine 模式打开 # 修改以下语句中的RewriteBase 后的地址为你的论坛目录地址,如果程序放在根目录中,为 /,如果是相对论坛根目录是其他目录则写为 /{目录名},如:在bbs 目录下,则写为 /bbs # Rewrite 系统规则请勿修改 |
用 UltraEdit 写好规则后,按F12,在文件另存为的窗口上,有个“格式”选项,选“utf-8 -无BOM “保存。然后把“.htaccess”上传到论坛根目录。
然后在进入后台 --> 全局-->优化设置-->搜索引擎优化 。 其他保持不变,就把“主题内容页”规则改为:
| thread-{tid}-{page}.html |

保存设置再更新一下缓存就可以了。
5,解决重复URL的问题和屏蔽垃圾页面
Discuz! X1.5 还是不可避免的出现重复url的问题。 (希望有渠道的朋友能把这些问题反馈给Discuz相关人员)
这些重复的url即浪费了爬虫大量的时间,又使网站的原创性受到损害。所以一定要屏蔽很多重复页面。
另外还要干掉一些垃圾页面,所谓垃圾页面就是一些没什么SEO价值的页面,也帮助爬虫节约时间。
解决这个问题,最好是用robots.txt文件来解决。因为里面的规则是最强势的,所有爬虫第一次访问一个域名,第一个动作都是下载这个robots.txt文件并读取里面的规则。 其他一些nofollow和rel=canonical等标签适当的时候再用。
虽然Discuz默认写了一些robots规则,但是还是不够理想。
根据从首页的代码中发现的问题,需要在robots.txt里增加的规则有:
| Disallow: /forum.php$ Disallow: /search-search-adv-yes.html Disallow: /space-username-* Disallow: /forum.php?gid= Disallow: /home.php?mod=space&username= Disallow: /forum.php?showoldetails= Disallow: /home-space-do-friend-view-online-type-member.html Disallow: /space-uid-* |
根据在板块帖子列表页面发现的问题,需要在robots.txt里增加的规则有:
| Disallow: /search.php$ Disallow: /forum-forumdisplay-fid-* |
根据在帖子详细信息页面看到的问题,需要在robots.txt里增加的规则有:
| Disallow: /forum-viewthread-tid-*-extra-page%3D.html$ Disallow: /forum.php?mod=viewthread&tid= Disallow: /forum-viewthread-tid-*-page-*-authorid-*.html Disallow: /forum-viewthread-tid-*-extra-page%3D-ordertype-*.html Disallow: /forum-viewthread-action-printable-tid-*.html Disallow: /home-space-uid-* |
至于为什么要写这些规则,由于描述起来实在啰嗦,所以大家自行到源代码里查看为什么。
robots的写法是很灵活的。
可以看一下百度的robots写法指南:
http://www.baidu.com/search/robots.html
以及google网站管理员中心的说明:
http://www.google.com/support/webmasters/bin/answer.py?hl=cn&answer=156449
robots.txt写到这里并不是结束,还有两件事情要做。
1,因为robots.txt和nofollow是不同的意思,所以robots.txt并不能代替nofollow。以上这些需要屏蔽的地方还需要用nofollow标注一下。 不过因为要改的源码太多,暂时先不动。需要用nofollow,还有一个原因是某些搜索引擎并不遵守自己所定下的robots规则。
2,因为只看过论坛中的三类主要页面,还有很多页面没查看过,难免会有漏掉的地方,所以需要以后经常到日志中查看爬虫的轨迹,看看爬虫还有哪些抓取问题。
未完待续......